Amazon S3 Hosting
Posted: Fri Jun 16, 2017 6:35 pm
Hey all,
With dropbox ending their support of HTML rendering in a few short months, I went through the process of finding a suitable host that was easy to use, cheap and reliable. And in the end, 2 out of 3 isn't bad
Before I landed on AWS, I tried out boxhop.io, github pages, and few other dropbox integrated hosting solutions, however, I could never get them to read correctly (some would give XML errors, some wouldn't render, some would be blank, etc etc). After futzing around with that, I landed on Amazon's S3 hosting, however, ran into a series of unexplained issues. These issues are still a complete mystery to a novice such as myself, however, I'm leaving a few notes on here so that other users who are having the same issues can find some solutions. AWS is pretty great, just fairly complicated and not very intuitive.
Finally, big thanks to Tony for helping me through all of this: its nice to know that S3 hosting should and does work, despite the various peculiarities on my own end.
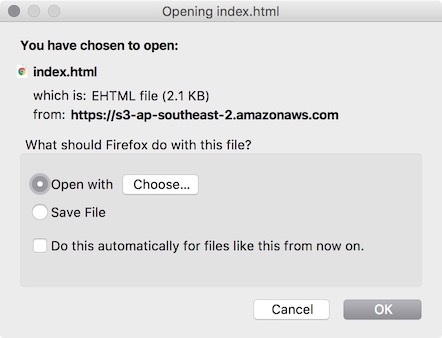
The issue seems to come down to metadata tagging. By default, most (if not all) objects come in as key "content-type" and value "binary/octet-stream". I don't 100% know why this is or why it causes a mess up, but, on some test buckets it would cause the index.html file to ask to be downloaded instead of rendered as a page, and if I went directly to any of the PNG button url's, it would ask to download.
Additionally, apparently AWS S3 doesn't use folders/sub-folders. It only show them to us because we are used to them, but everything in a bucket has a flat storage system (taken from their documentation). So because of this, when I bring in the html file, xml file and various subfolders, it doesn't apply the correct metadata tagging to any of the items in the subfolders.
And here's where it gets tricky, but I can confirm it seems to work:
Create new bucket
Make sure under Step 3 that public permissions are set to “read”
Within the bucket, hit upload and drag/drop all files from your pano2vr output EXCEPT the “images” folder
Under permissions, make sure public is set to “read”
Under properties, under metadata, clear the “x-amz-meta-” and change the top header to “content-disposition” with a blank value
Hit upload
Within the aws console, create a new folder called “images”
Within the AWS images folder, hit upload
drag/drop all content under your pano2vr “images” folder to the upload box
As above, make sure public permissions are set to “read”
As above, clear the metadata and change top header to “content-disposition”
Upload
After all that, I got 2x index.html to read fine on 2 separate buckets. I'll freely admit I have no idea what difference the metadata makes or why it is so dumb, but at the end of the day, I got it working for me. It all comes down to metadata for images on subfolders defaulting to octet-stream as the "content-type" key, where if I can get them to read properly as "image/png", its all good. And the kicker is according to AWS documentation, once an object is uploaded, the metadata can not be changed, so you have to make sure it is configured properly for the upload or delete and do it again.
With dropbox ending their support of HTML rendering in a few short months, I went through the process of finding a suitable host that was easy to use, cheap and reliable. And in the end, 2 out of 3 isn't bad
Before I landed on AWS, I tried out boxhop.io, github pages, and few other dropbox integrated hosting solutions, however, I could never get them to read correctly (some would give XML errors, some wouldn't render, some would be blank, etc etc). After futzing around with that, I landed on Amazon's S3 hosting, however, ran into a series of unexplained issues. These issues are still a complete mystery to a novice such as myself, however, I'm leaving a few notes on here so that other users who are having the same issues can find some solutions. AWS is pretty great, just fairly complicated and not very intuitive.
Finally, big thanks to Tony for helping me through all of this: its nice to know that S3 hosting should and does work, despite the various peculiarities on my own end.
The issue seems to come down to metadata tagging. By default, most (if not all) objects come in as key "content-type" and value "binary/octet-stream". I don't 100% know why this is or why it causes a mess up, but, on some test buckets it would cause the index.html file to ask to be downloaded instead of rendered as a page, and if I went directly to any of the PNG button url's, it would ask to download.
Additionally, apparently AWS S3 doesn't use folders/sub-folders. It only show them to us because we are used to them, but everything in a bucket has a flat storage system (taken from their documentation). So because of this, when I bring in the html file, xml file and various subfolders, it doesn't apply the correct metadata tagging to any of the items in the subfolders.
And here's where it gets tricky, but I can confirm it seems to work:
Create new bucket
Make sure under Step 3 that public permissions are set to “read”
- Screenshot 2017-06-16 12.09.44.jpg (78.75 KiB) Viewed 15081 times
Within the bucket, hit upload and drag/drop all files from your pano2vr output EXCEPT the “images” folder
Under permissions, make sure public is set to “read”
- Screenshot 2017-06-16 12.11.02.jpg (78.64 KiB) Viewed 15081 times
- Screenshot 2017-06-16 12.12.01.jpg (82.05 KiB) Viewed 15081 times
Hit upload
Within the aws console, create a new folder called “images”
Within the AWS images folder, hit upload
drag/drop all content under your pano2vr “images” folder to the upload box
As above, make sure public permissions are set to “read”
As above, clear the metadata and change top header to “content-disposition”
Upload
After all that, I got 2x index.html to read fine on 2 separate buckets. I'll freely admit I have no idea what difference the metadata makes or why it is so dumb, but at the end of the day, I got it working for me. It all comes down to metadata for images on subfolders defaulting to octet-stream as the "content-type" key, where if I can get them to read properly as "image/png", its all good. And the kicker is according to AWS documentation, once an object is uploaded, the metadata can not be changed, so you have to make sure it is configured properly for the upload or delete and do it again.